|
I am currently a research scientist at Google Zurich. Prior to that, I was a post-doctoral researcher with Luc Van Gool in the Computer Vision Lab at ETH Zurich. I completed my PhD summa cum laude at the Max Planck Institute Informatics under the supervision of Bernt Schiele and Zeynep Akata. My research focuses on vision-language model pretraining and its applications in vision tasks. Email / CV / Google Scholar |

|
|
|
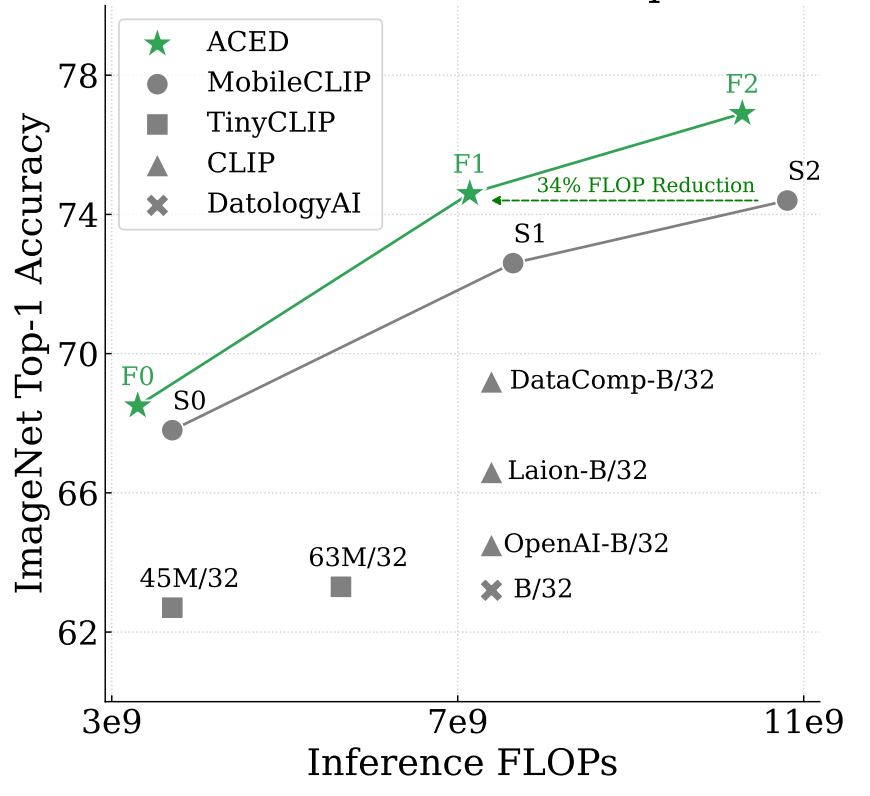
Chiara Plizzari, Alessio Tonioni, Yongqin Xian, Ace Kulshrestha, Federico Tombari CVPR, 2025 |
|
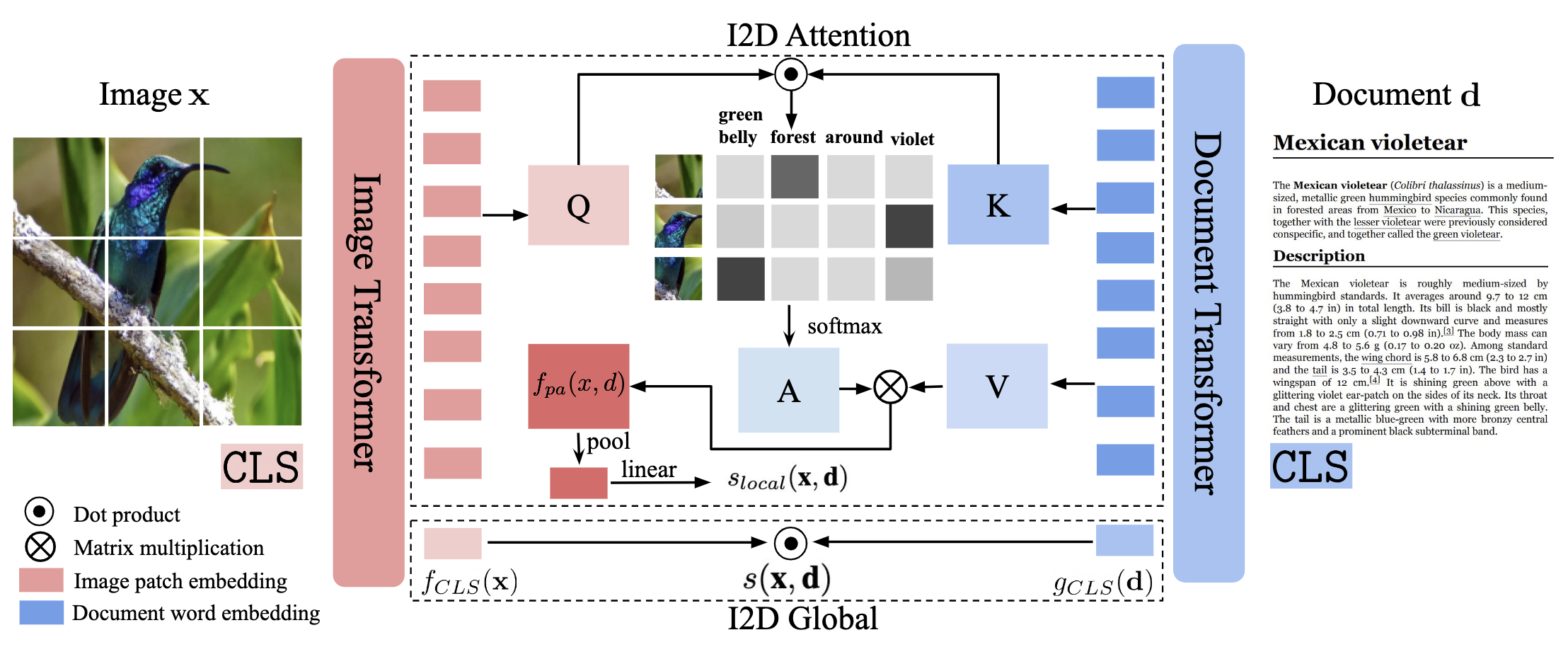
Vishaal Udandarao*, Nikhil Parthasarathy*, Muhammad Ferjad Naeem Talfan Evans, Samuel Albanie, Federico Tombari, Yongqin Xian, Alessio Tonioni, Olivier J. Henaff CVPR, 2025 |
|
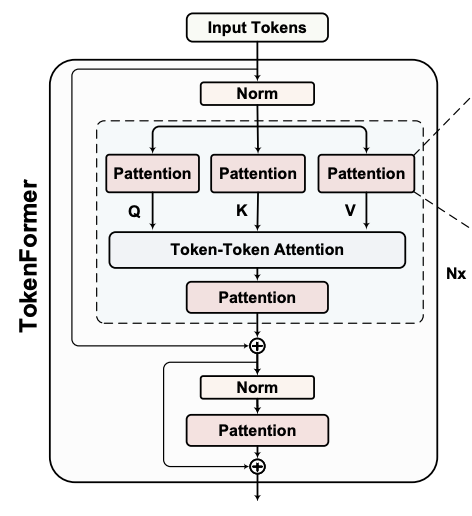
Haiyang Wang, Yue Fan, Muhammad Ferjad Naeem, Yongqin Xian Jan Eric Lenssen, Liwei Wang, Federico Tombari, Bernt Schiele ICLR, 2025 |
|
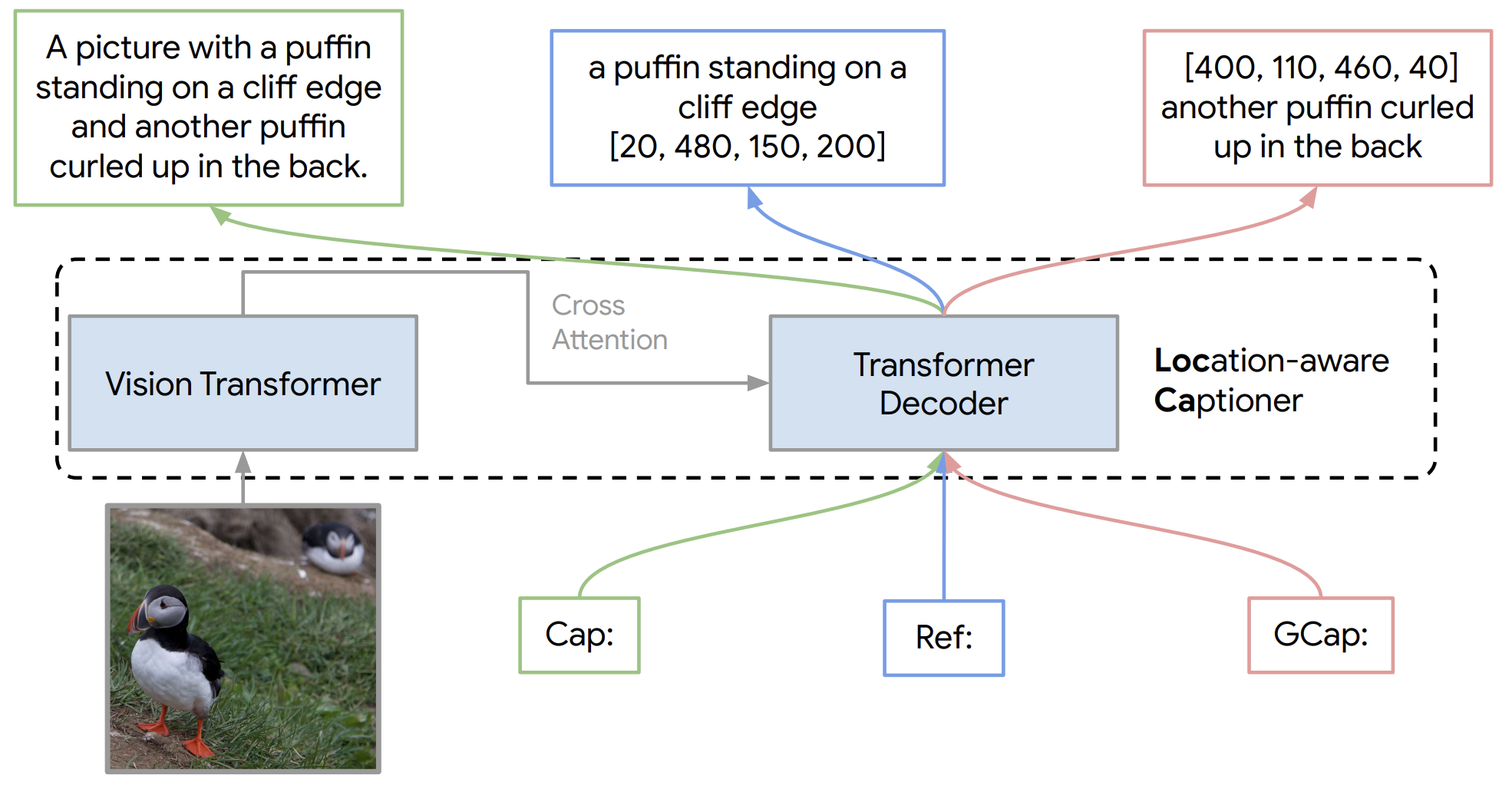
Bo Wan, Michael Tschannen, Yongqin Xian, Filip Pavetic, Ibrahim Alabdulmohsin, Xiao Wang, André Susano Pinto, Andreas Steiner, Lucas Beyer, Xiaohua Zhai NeurIPS, 2024 |
|
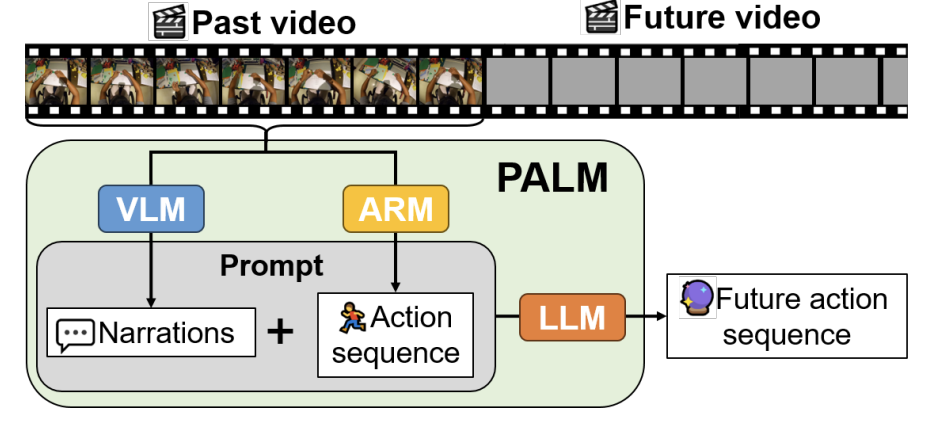
Sanghwan Kim, Daoji Huang, Yongqin Xian, Otmar Hilliges, Luc Van Gool, Xi Wang ECCV, 2024 |
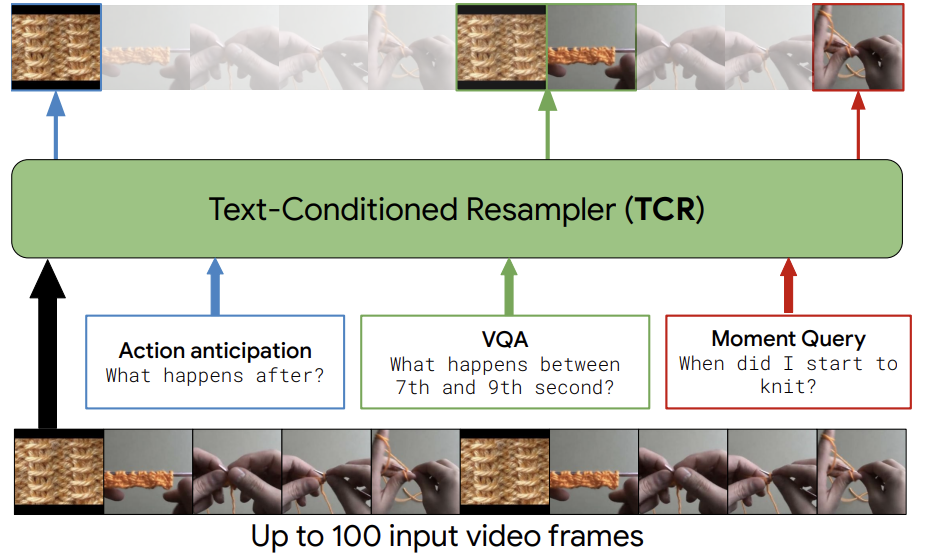
|
Bruno Korbar, Yongqin Xian, Alessio Tonioni, Andrew Zisserman, Federico Tombari ECCV, 2024 |
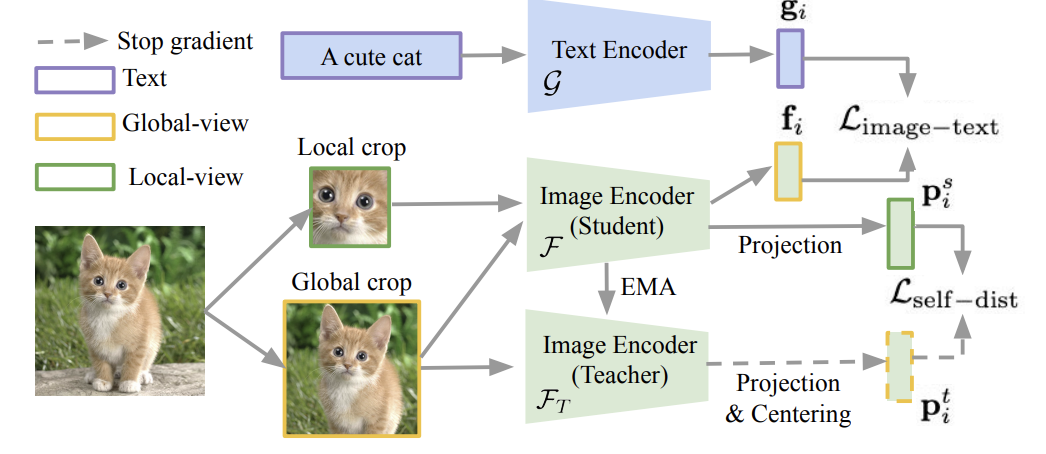
|
Muhammad Ferjad Naeem, Yongqin Xian, Xiaohua Zhai, Lukas Hoyer, Luc Van Gool, Federico Tombari ECCV, 2024 |
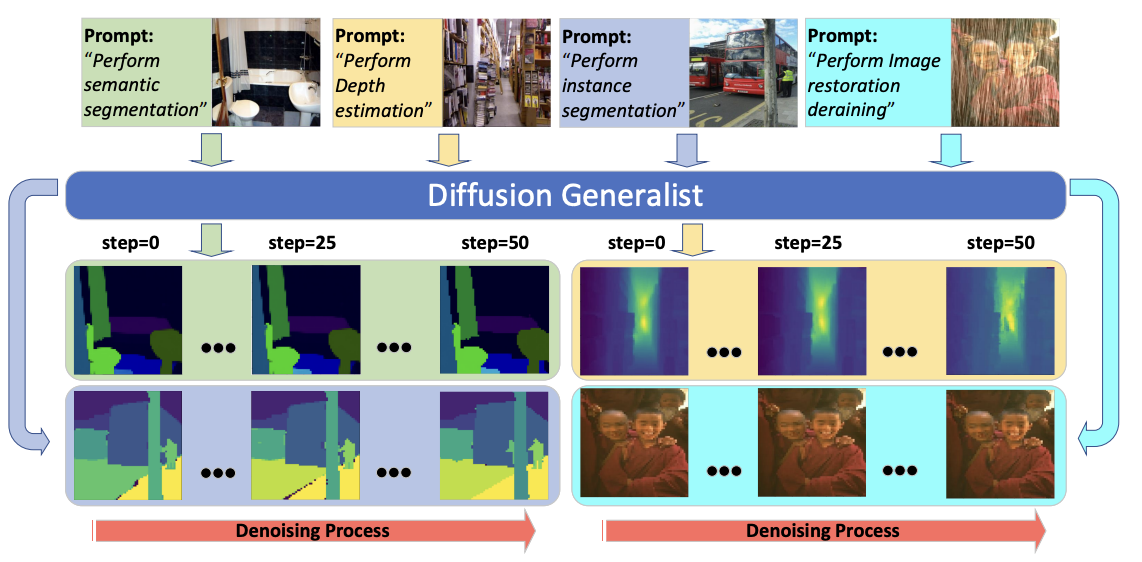
|
Yue Fan, Yongqin Xian, Xiaohua Zhai, Alexander Kolesnikov, Muhammad Ferjad Naeem, Bernt Schiele, Federico Tombari CVPR Workshop on What is Next in Multimodal Foundation Models, 2024 |
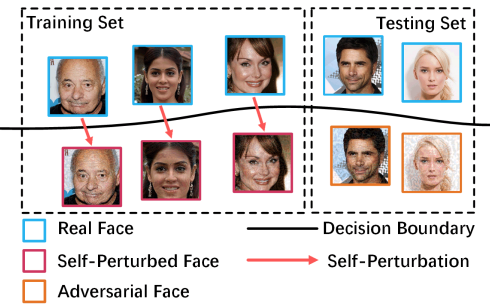
|
Qian Wang, Yongqin Xian, Hefei Ling, Jinyuan Zhang, Ping Li, Xiaorui Lin, Jiazhong Chen, Ning Yu IJCAI, 2023 |
|
Saurabh Sharma, Yongqin Xian, Ning Yu, Ambuj Singh IJCAI, 2023 |
|
Anurag Das, Yongqin Xian, Dengxin Dai, Bernt Schiele CVPR, 2023 |
|
Jiezhang Cao, Qin Wang, Yongqin Xian, Yawei Li, Bingbing Ni, Zhiming Pi, Kai Zhang, Yulun Zhang, Radu Timofte, Luc Van Gool CVPR, 2023 |
|
Muhammad Ferjad Naeem*, Muhammad Gul Zain Ali Khan*, Yongqin Xian, Muhammad Zeshan Afzal, Didier Stricker, Luc Van Gool, Federico Tombari *Equal contribution CVPR, 2023 |
|
Muhammad Ferjad Naeem, Yongqin Xian, Luc Van Gool, Federico Tombari NeurIPS, 2022 |
|
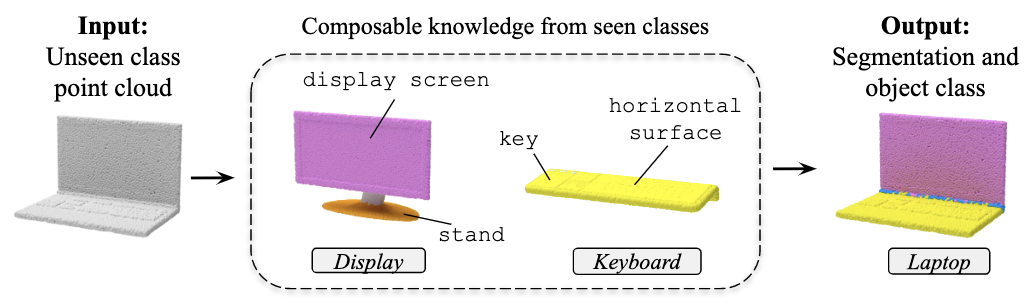
Muhammad Ferjad Naeem*, Evin Pınar Örnek*, Yongqin Xian, Luc Van Gool, Federico Tombari *Equal contribution ECCV, 2022 |
|
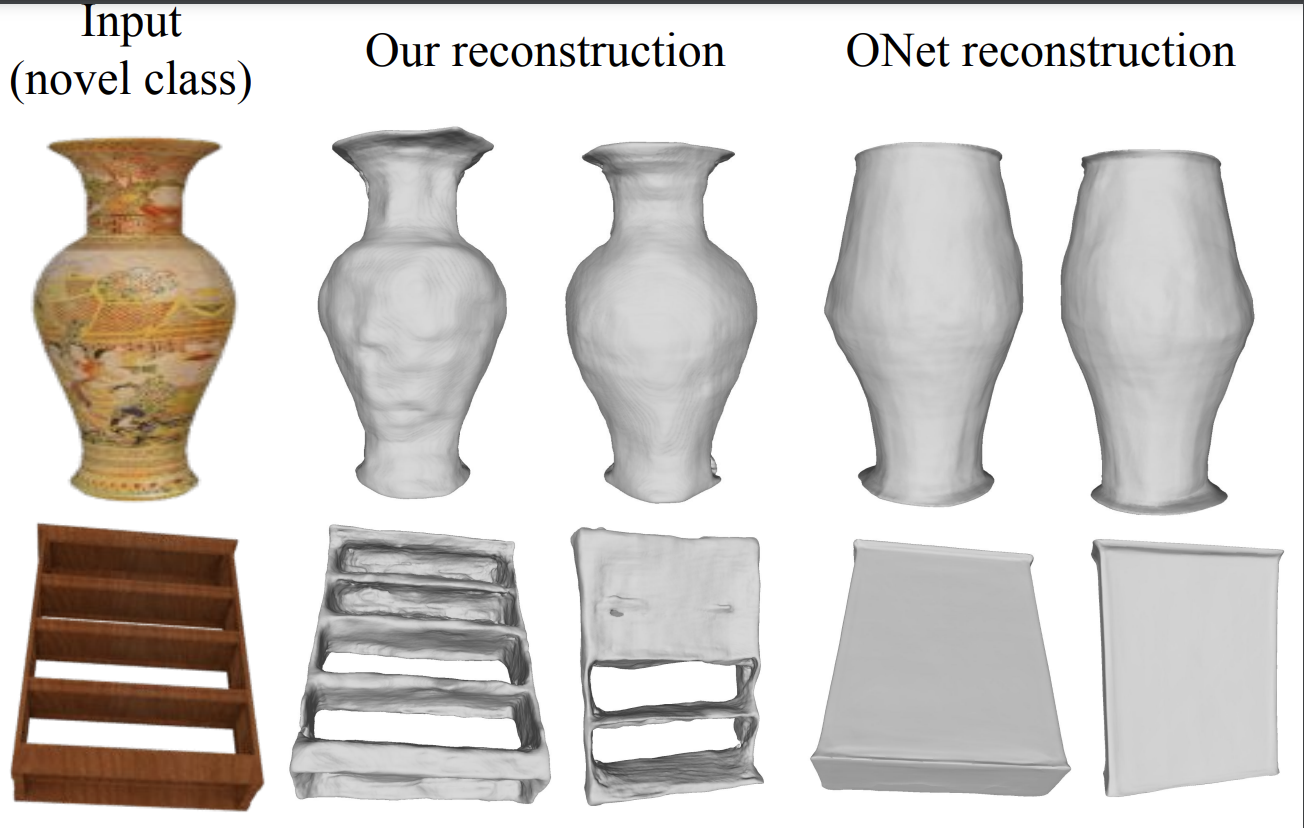
Yongqin Xian, Julian Chibane, Bharat Lal Bhatnagar, Bernt Schiele, Zeynep Akata, Gerard Pons-Moll 3DV, 2022 (Oral, Best Paper Honourable Mention) |
|
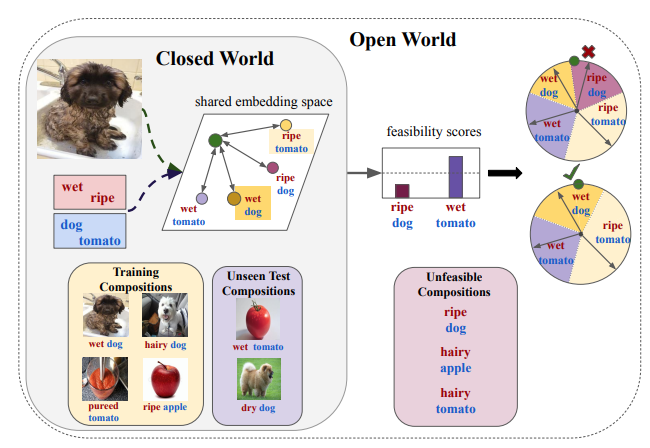
Massimiliano Mancini, Muhammad Ferjad Naeem, Yongqin Xian, Zeynep Akata TPAMI, 2022 |
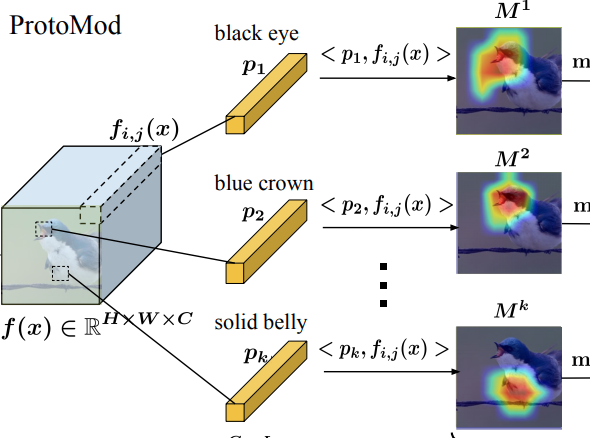
|
Wenjia Xu, Yongqin Xian, Jiuniu Wang, Bernt Schiele, Zeynep Akata IJCV, 2022 |
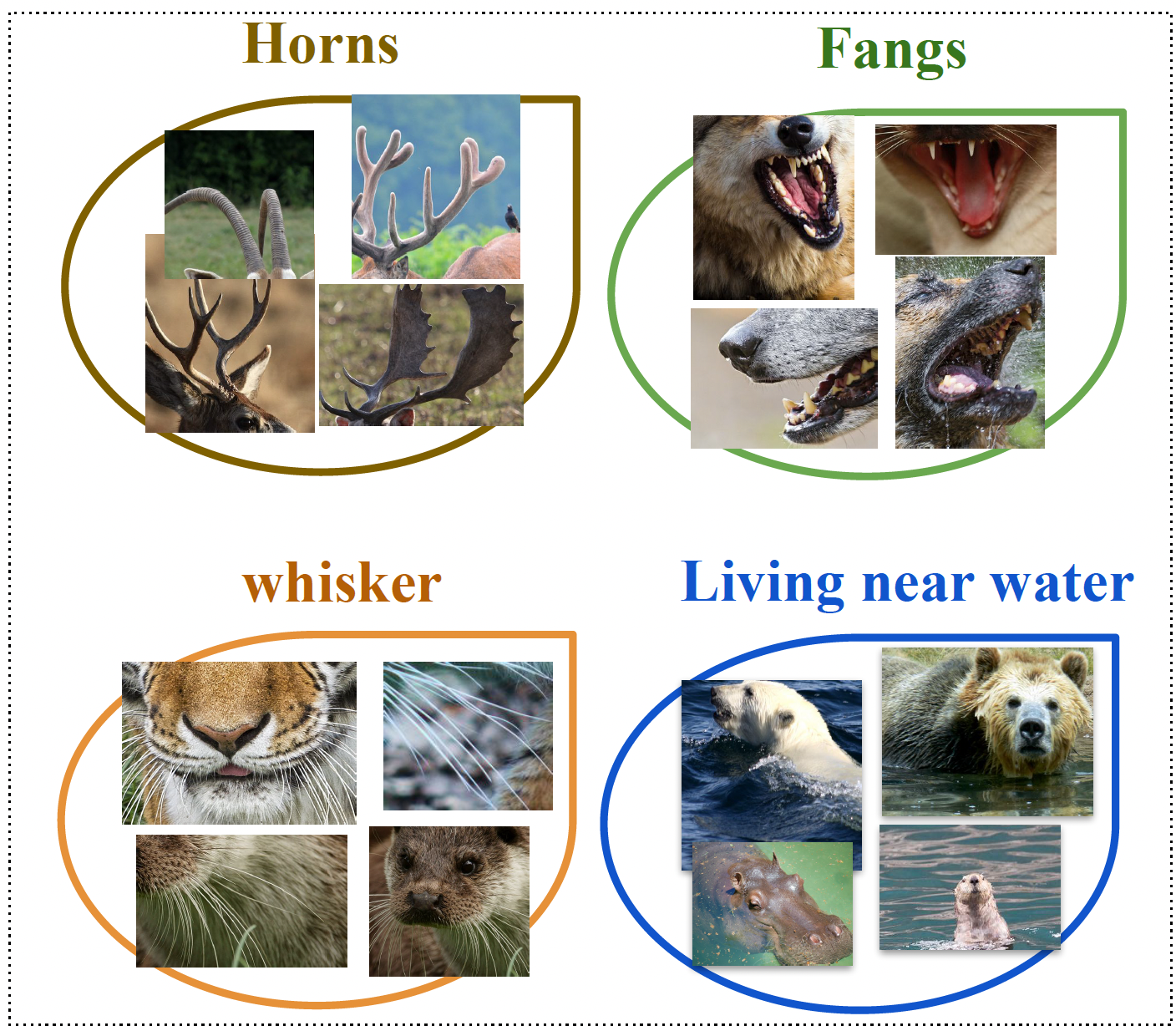
|
Wenjia Xu, Yongqin Xian, Jiuniu Wang, Bernt Schiele, Zeynep Akata CVPR, 2022
arxiv /
|
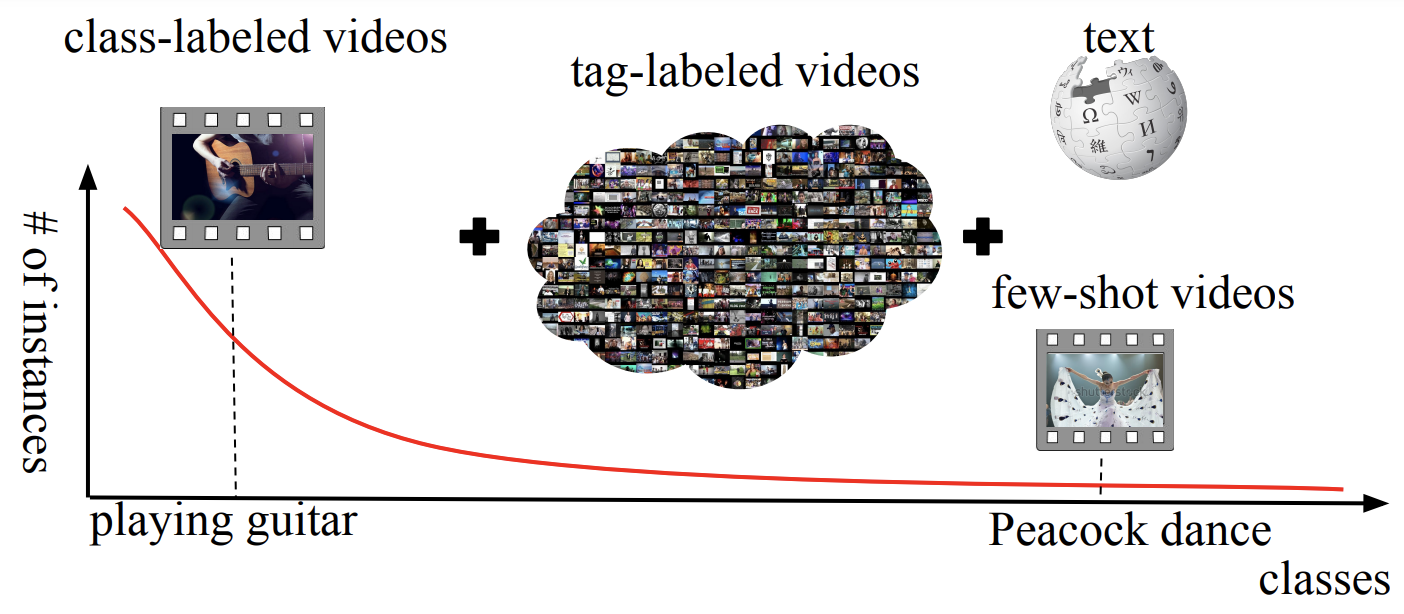
|
Yongqin Xian, Bruno Korbar, Matthijs Douze, Lorenzo Torresani, Bernt Schiele, Zeynep Akata TPAMI, 2021 |
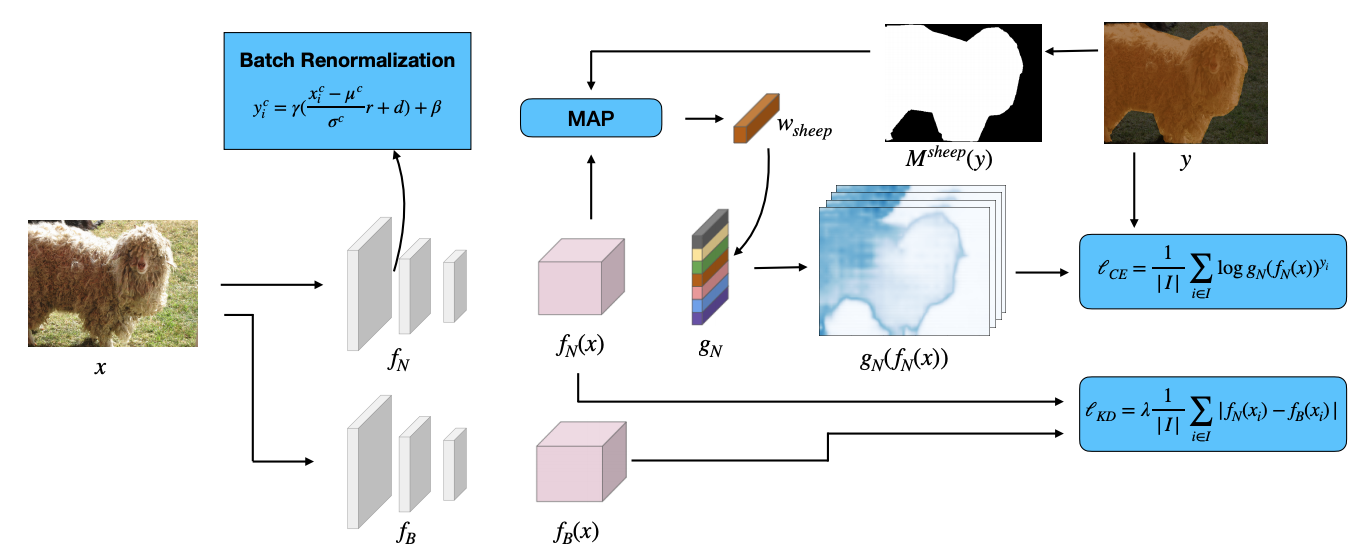
|
Fabio Cermelli, Massimiliano Mancini, Yongqin Xian, Zeynep Akata, Barbara Caputo BMVC 2021 |
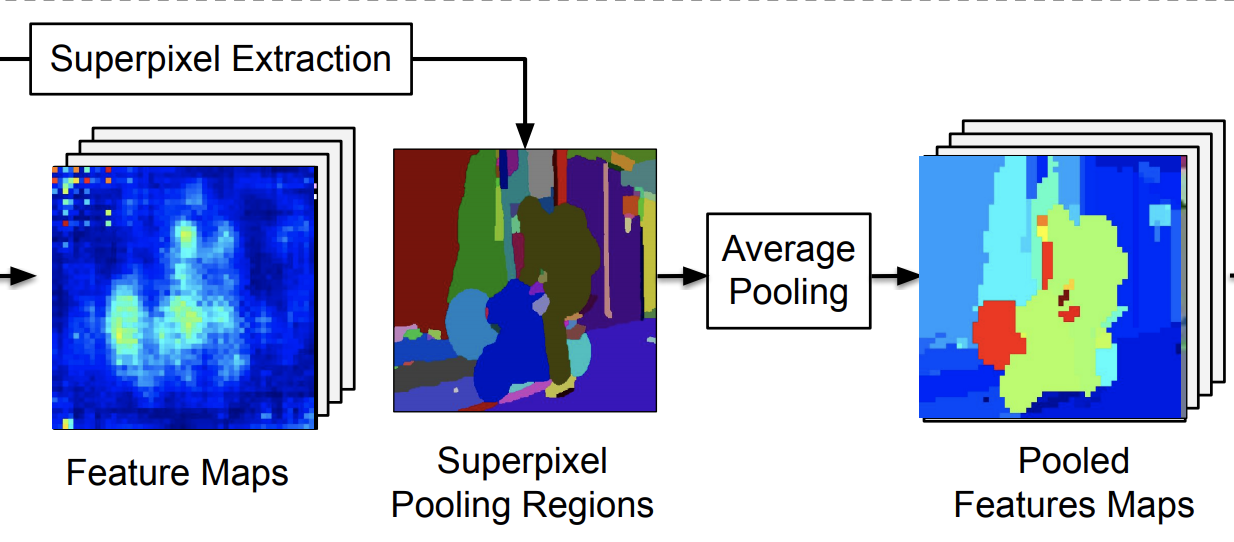
|
Anurag Das, Yongqin Xian, Yang He, Bernt Schiele, Zeynep Akata GCPR, 2021 (Best Master's Thesis Award)
arxiv /
|
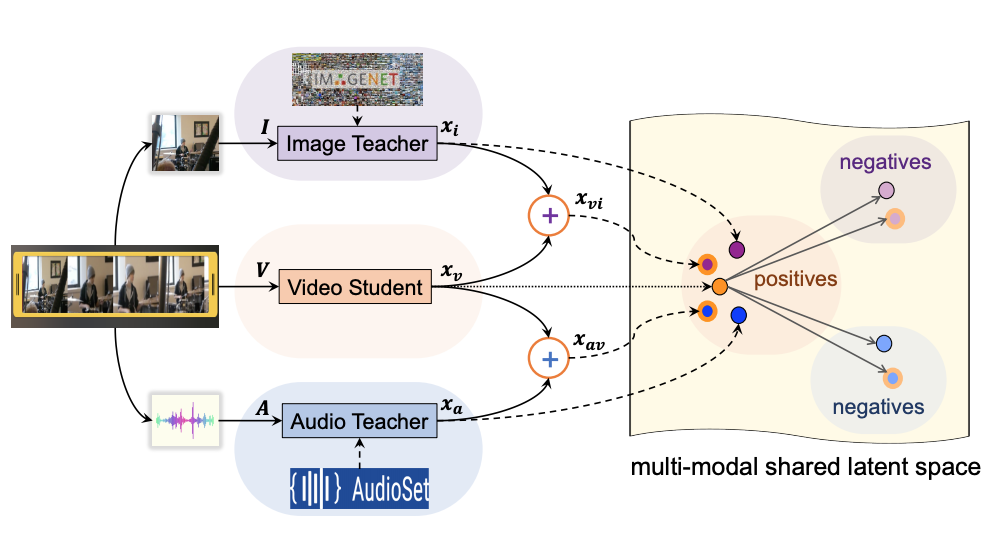
|
Yanbei Chen, Yongqin Xian, Almut Sophia Koepke, Zeynep Akata CVPR, 2021 |
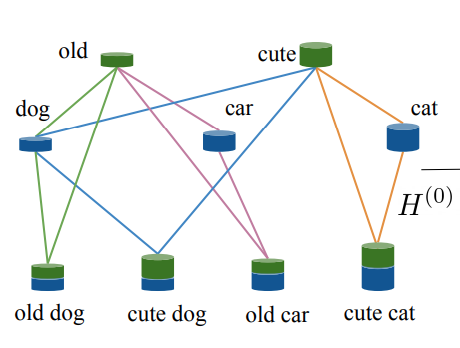
|
Muhammad Ferjad Naeem, Yongqin Xian, Federico Tombari, Zeynep Akata CVPR, 2021 |
|
|
Massimiliano Mancini*, Muhammad Ferjad Naeem*, Yongqin Xian, Zeynep Akata CVPR, 2021 |
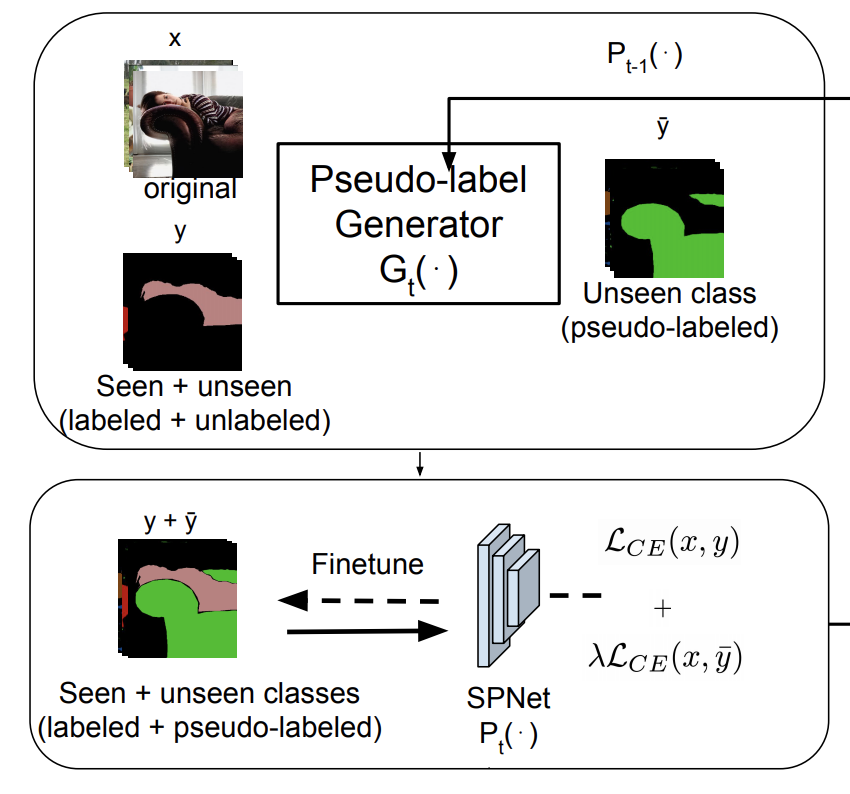
|
Giuseppe Pastore, Fabio Cermelli, Yongqin Xian, Massimiliano Mancini, Zeynep Akata, Barbara Caputo CVPR 2021 Workshop on Learning with Limited and Imperfect Data |
|
|
Wenjia Xu, Yongqin Xian, Jiuniu Wang, Bernt Schiele, Zeynep Akata NeurIPS, 2020 |
|
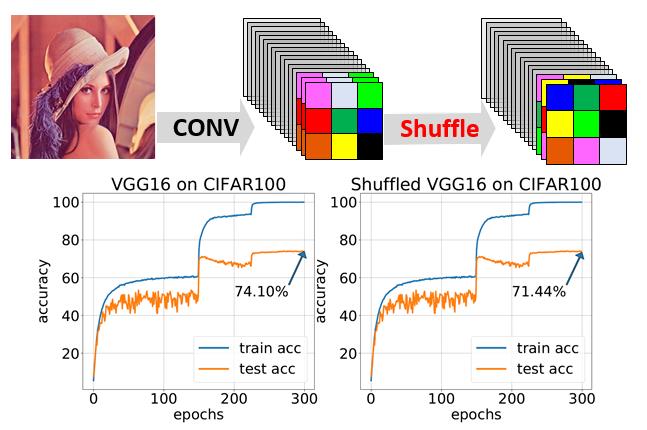
Yue Fan, Yongqin Xian, Max Maria Losch, Bernt Schiele GCPR, 2020 |

|
Yongqin Xian, Bruno Korbar, Matthijs Douze, Bernt Schiele, Zeynep Akata, Lorenzo Torresani ECCV Workshop, 2020 |
|
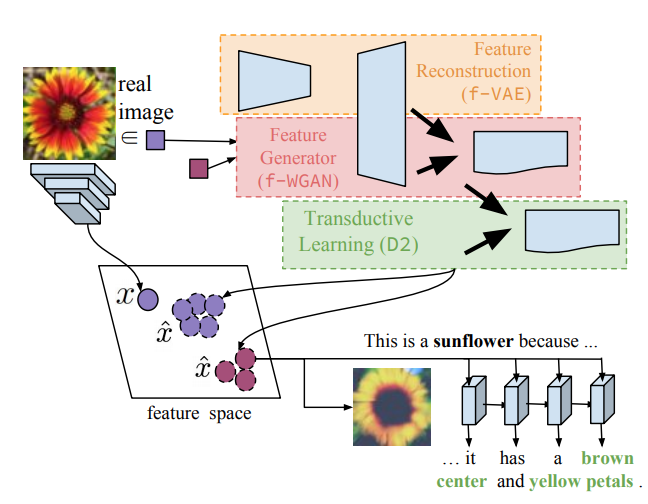
Yongqin Xian, Saurabh Sharma, Bernt Schiele, Zeynep Akata CVPR, 2019 |
|
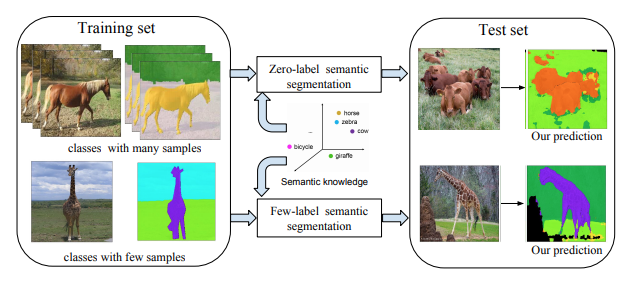
Yongqin Xian*, Subhabrata Choudhury*, Yang He, Bernt Schiele, Zeynep Akata CVPR, 2019 |

|
Yongqin Xian, Christoph H. Lampert, Bernt Schiele, Zeynep Akata TPAMI, 2018 |
|
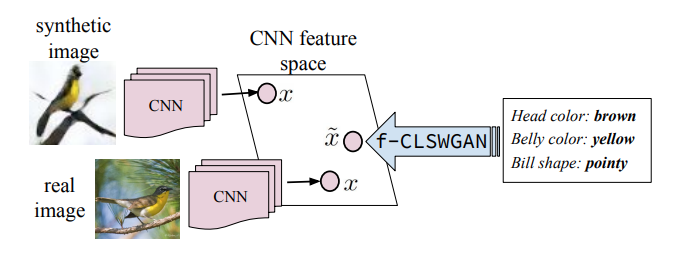
Yongqin Xian, Tobias Lorenz, Bernt Schiele, Zeynep Akata CVPR, 2018 |
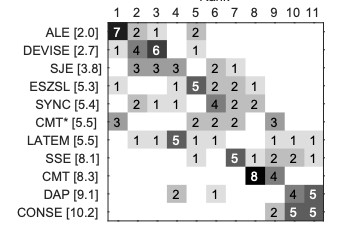
|
Yongqin Xian, Bernt Schiele, Zeynep Akata CVPR, 2017 |
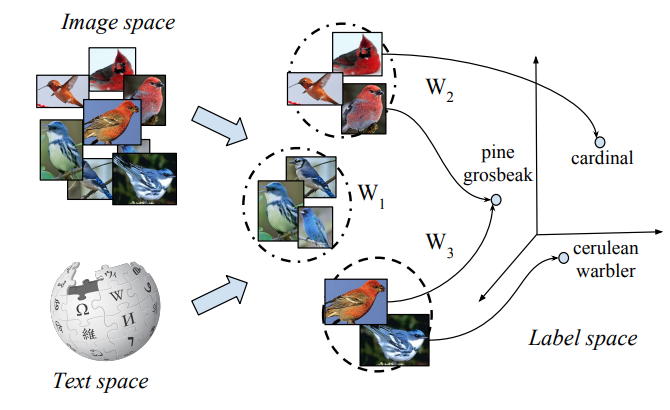
|
Yongqin Xian, Zeynep Akata, Gaurav Sharma, Quynh Nguyen, Matthias Hein, Bernt Schiele CVPR, 2016 |